

You can use a variety
of criteria for organizing WebLogic Server instances
into domains. For instance, you might choose to allocate resources to multiple
domains based on logical divisions of the hosted application, geographical
considerations, or the number or complexity of the resources under management.
For additional information about domains see Understanding
Domain Configuration.
Domain
Restrictions
In designing your
domain configuration, note the following restrictions:
Each domain requires
its own Administration Server for performing management activities. When you
use the Administration Console to perform management and monitoring tasks, you
can switch back and forth between domains, but in doing so, you are connecting
to different Administration Servers.
All Managed Servers
in a cluster must reside in the same domain; you cannot split a cluster over
multiple domains.
All Managed Servers
in a domain must run the same version of the WebLogic
Server software. The Administration Server may run either the same version as
the Managed Servers in the domain, or a later service pack.
If you have created
multiple domains, each domain must reference its own database schema. You
cannot share a configured resource or subsystem between domains. For example,
if you create a JDBC data source in one domain, you cannot use it with a
Managed Server or cluster in another domain. Instead, you must create a similar
data source in the second domain. Furthermore, two or more system resources
cannot have the same name.

All instances of WebLogic Server use a root
directory to store their working copy of the domain's configuration files, to
store runtime data, and to provide the context for any relative pathnames in
the server's configuration. An Administration Server always uses the domain
directory as its root directory. A Managed Server can use the domain directory
but can also use any other directory that you define.
Applications can use
the following resources and services:
Security providers,
which are modular components that handle specific aspects of security, such as
authentication and authorization.
Resource adapters,
which are system libraries specific to Enterprise Information Systems (EIS) and
provide connectivity to an EIS.
Diagnostics and
monitoring services.
JDBC data sources,
which enable applications to connect to databases.
Mail sessions.
XML entity caches and
registry of XML parsers and transformer factories
Messaging services
such as JMS servers and store-and-forward services
Persistent store,
which is a physical repository for storing data, such as persistent JMS
messages. It can be either a JDBC-accessible database or a disk-based file.
Startup classes,
which are Java programs that you create to provide custom, system-wide services
for your applications.
Work Managers, which
determine how an application prioritizes the execution of its work based on
rules you define and by monitoring actual runtime performance. You can create
Work Mangers for entire WebLogic Server domains or
for specific application components.
Work Contexts, which
enable applications to pass properties to a remote context without including
the properties in a remote call.

Do
you need to explicitly configure the admin server?
Administration
Server
The Administration
Server operates as the central control entity for the configuration of the
entire domain. It maintains the domain's configuration documents and
distributes changes in the configuration documents to Managed Servers. You can
also use the Administration Server as a central location from which to monitor
all resources in a domain.
To interact with the
Administration Server, you can use the Administration Console, WLST, or create
your own JMX client. See Summary of System
Administration Tools and APIs in Overview of WebLogic Server System Administration to modify the domain's configuration.
Each WebLogic Server domain must
have one server instance that acts as the Administration Server.
In each domain, one WebLogic Server instance acts
as the Administration Server—the server instance which configures, manages, and
monitors all other server instances and resources in the domain. Each
Administration Server manages one domain only. If a domain contains multiple
clusters, each cluster in the domain has the same Administration Server.
More Thoughts:
-MSI Mode
-Disabling the Admin
Console

Managed Servers host
business applications, application components, Web services, and their
associated resources. To optimize performance, Managed Servers maintain a
read-only copy of the domain's configuration document.
Managed Servers can
use the following resources:
Machine definitions
that identify a particular, physical piece of hardware. A machine definition is
used to associate a computer with the Managed Servers it hosts. This
information is used by Node Manager in restarting a failed Managed Server, and
by a clustered Managed Server in selecting the best location for storing
replicated session data. For more information about Node Manager, see Using Node
Manager to Control Servers
in Managing
Server Startup and Shutdown.
Network channels that
define default ports, protocols, and protocol settings that a Managed Server
uses to communicate with clients. After creating a network channel, you can
assign it to any number of Managed Servers and clusters in the domain. For more
information, see Configuring
Network Resources
in Configuring
WebLogic
Server Environments.
Virtual hosting,
which defines a set of host names to which WebLogic
Server instances (servers) or clusters respond. When you use virtual hosting,
you use DNS to specify one or more host names that map to the IP address of a
server or cluster. You also specify which Web applications are served by each
virtual host.

When a Managed Server
starts up, it connects to the domain's Administration Server to synchronize its
configuration document with the document that the Administration Server
maintains.

What
Is a WebLogic
Server Cluster?
A WebLogic Server cluster
consists of multiple WebLogic Server server instances running
simultaneously and working together to provide increased scalability and
reliability. A cluster appears to clients to be a single WebLogic Server instance. The
server instances that constitute a cluster can run on the same machine, or be
located on different machines. You can increase a cluster's capacity by adding
additional server instances to the cluster on an existing machine, or you can
add machines to the cluster to host the incremental server instances. Each
server instance in a cluster must run the same version of WebLogic Server.
How
Does a Cluster Relate to a Domain?
A cluster is part of
a particular WebLogic Server domain.
A domain is an
interrelated set of WebLogic Server resources
that are managed as a unit. A domain includes one or more WebLogic Server instances,
which can be clustered, non-clustered, or a combination of clustered and
non-clustered instances. A domain can include multiple clusters. A domain also
contains the application components deployed in the domain, and the resources
and services required by those application components and the server instances
in the domain. Examples of the resources and services used by applications and
server instances include machine definitions, optional network channels,
connectors, and startup classes.
You can use a variety
of criteria for organizing WebLogic Server instances
into domains. For instance, you might choose to allocate resources to multiple
domains based on logical divisions of the hosted application, geographical
considerations, or the number or complexity of the resources under management.
For additional information about domains see Understanding
Domain Configuration.
In each domain, one WebLogic Server instance acts
as the Administration Server—the server instance which configures, manages, and
monitors all other server instances and resources in the domain. Each
Administration Server manages one domain only. If a domain contains multiple
clusters, each cluster in the domain has the same Administration Server.
All server instances
in a cluster must reside in the same domain; you cannot "split" a
cluster over multiple domains. Similarly, you cannot share a configured
resource or subsystem between domains. For example, if you create a JDBC
connection pool in one domain, you cannot use it with a server instance or
cluster in another domain. (Instead, you must create a similar connection pool
in the second domain.)
Clustered WebLogic Server instances
behave similarly to non-clustered instances, except that they provide failover
and load balancing. The process and tools used to configure clustered WebLogic Server instances are
the same as those used to configure non-clustered instances. However, to
achieve the load balancing and failover benefits that clustering enables, you
must adhere to certain guidelines for cluster configuration.
To understand how the
failover and load balancing mechanisms used in WebLogic
Server relate to particular configuration options see Load
Balancing in a Cluster,
and Failover and
Replication in a Cluster.
Detailed
configuration recommendations are included throughout the instructions in Setting up WebLogic Clusters.
What
Are the Benefits of Clustering?
A WebLogic Server cluster
provides these benefits:
Scalability The
capacity of an application deployed on a WebLogic
Server cluster can be increased dynamically to meet demand. You can add server
instances to a cluster without interruption of service—the application
continues to run without impact to clients and end users.
High-Availability In
a WebLogic Server cluster,
application processing can continue when a server instance fails. You
"cluster" application components by deploying them on multiple server
instances in the cluster—so, if a server instance on which a component is
running fails, another server instance on which that component is deployed can
continue application processing.
The choice to cluster
WebLogic Server instances is
transparent to application developers and clients. However, understanding the
technical infrastructure that enables clustering will help programmers and
administrators maximize the scalability and availability of their applications.
What
Are the Key Capabilities of a Cluster?
This section defines,
in non-technical terms, the key clustering capabilities that enable scalability
and high availability.
Application Failover
Simply put, failover means that when an application component (typically
referred to as an "object" in the following sections) doing a
particular "job"—some set of processing tasks—becomes unavailable for
any reason, a copy of the failed object finishes the job.
For the new object to
be able to take over for the failed object:
There must be a copy
of the failed object available to take over the job.
There must be
information, available to other objects and the program that manages failover,
defining the location and operational status of all objects—so that it can be
determined that the first object failed before finishing its job.
There must be
information, available to other objects and the program that manages failover,
about the progress of jobs in process—so that an object taking over an
interrupted job knows how much of the job was completed before the first object
failed, for example, what data has been changed, and what steps in the process
were completed. WebLogic Server uses
standards-based communication techniques and facilities— including IP sockets and the Java Naming
and Directory Interface (JNDI)—to
share and maintain information about the availability of objects in a cluster.
These techniques allow WebLogic Server to determine
that an object stopped before finishing its job, and where there is a copy of
the object to complete the job that was interrupted.
Note:For backward
compatibility with previous versions, WebLogic
Server also allows you to use multicast for communications between clusters.Information about what has been
done on a job is called state. WebLogic Server maintains
information about state using techniques called session replication and replica-aware
stubs. When a particular
object unexpectedly stops doing its job, replication techniques enable a copy
of the object pick up where the failed object stopped, and finish the job.
WebLogic Server supports
automatic and manual migration of a clustered server instance from one machine
to another. A Managed Server that can be migrated is referred to as a migratable
server. This feature is
designed for environments with requirements for high availability. The server
migration capability is useful for
Ensuring
uninterrupted availability of singleton services—services that must run on only a single server instance
at any given time, such as JMS and the JTA transaction recovery system, when
the hosting server instance fails. A Managed Server configured for automatic
migration will be automatically migrated to another machine in the even of
failure.
Easing the process of
relocating a Managed Server, and all the services it hosts, as part of a
planned system administration process. An administrator can initiate the
migration of a Managed Server from the Administration Console or command line.
The server migration process relocates a Managed Server in its
entirety—including IP addresses and hosted applications—to on of a predefined
set of available host machines.
Load Balancing Load
balancing is the even distribution of jobs and associated communications across
the computing and networking resources in your environment. For load balancing
to occur:
There must be
multiple copies of an object that can do a particular job.
Information about the
location and operational status of all objects must be available. WebLogic Server allows
objects to be clustered—deployed on multiple server instances—so that there are
alternative objects to do the same job. WebLogic
Server shares and maintains the availability and location of deployed objects
using unicast, IP sockets, and
JNDI.
Note:For backward
compatibility with previous versions, WebLogic
Server also allows you to use multicast for communications between clusters.
A detailed discussion
of how communications and replication techniques are employed by WebLogic Server is provided
in Communications In
a Cluster.



Servlets and
JSPs
WebLogic Server provides
clustering support for servlets and JSPs by
replicating the HTTP session state of clients that access clustered servlets and JSPs. WebLogic Server can maintain
HTTP session states in memory, a filesystem, or a database.
To enable automatic
failover of servlets and JSPs, session
state must persist in memory. For information about how failover works for servlets and JSPs, and for
related requirements and programming considerations, see HTTP Session
State Replication.
You can balance the servlet and JSP load across
a cluster using a WebLogic Server proxy plug-in
or external load balancing hardware. WebLogic
Server proxy plug-ins perform round robin load balancing. External load
balancers typically support a variety of session load balancing mechanisms. For
more information, see Load
Balancing for Servlets and JSPs.
EJBs
and RMI Objects
Load balancing and
failover for EJBs and RMI objects is handled using replica-aware
stubs, which can locate
instances of the object throughout the cluster. Replica-aware stubs are created
for EJBs and RMI objects as a result of the object compilation process. EJBs
and RMI objects are deployed homogeneously—to all the server instances in the cluster.
Failover for EJBs and
RMI objects is accomplished using the object's replica-aware stub. When a
client makes a call through a replica-aware stub to a service that fails, the
stub detects the failure and retries the call on another replica. To understand
failover support for different types of objects, see Replication and
Failover for EJBs and RMIs.
WebLogic Server clusters
support multiple algorithms for load balancing clustered EJBs and RMI objects:
round-robin, weight-based, random, round-robin-affinity, weight-based-affinity,
and random-affinity. By default, a WebLogic
Server cluster will use the round-robin method. You can configure a cluster to
use one of the other methods using the Administration Console. The method you
select is maintained within the replica-aware stub obtained for clustered
objects. For details, see Load
Balancing for EJBs and RMI Objects.


Server instances in a
WebLogic Server production
environment are often distributed across multiple domains, machines, and
geographic locations. Node Manager is a WebLogic
Server utility that enables you to start, shut down, and restart Administration
Server and Managed Server instances from a remote location. Although Node
Manager is optional, it is recommended if your WebLogic
Server environment hosts applications with high availability requirements.
A Node Manager
process is not associated with a specific WebLogic
domain but with a machine. You can use the same Node Manager process to control
server instances in any WebLogic Server domain, as
long as the server instances reside on the same machine as the Node Manager
process. Node Manager must run on each computer that hosts WebLogic Server instances --
whether Administration Server or Managed Server -- that you want to control
with Node Manager.



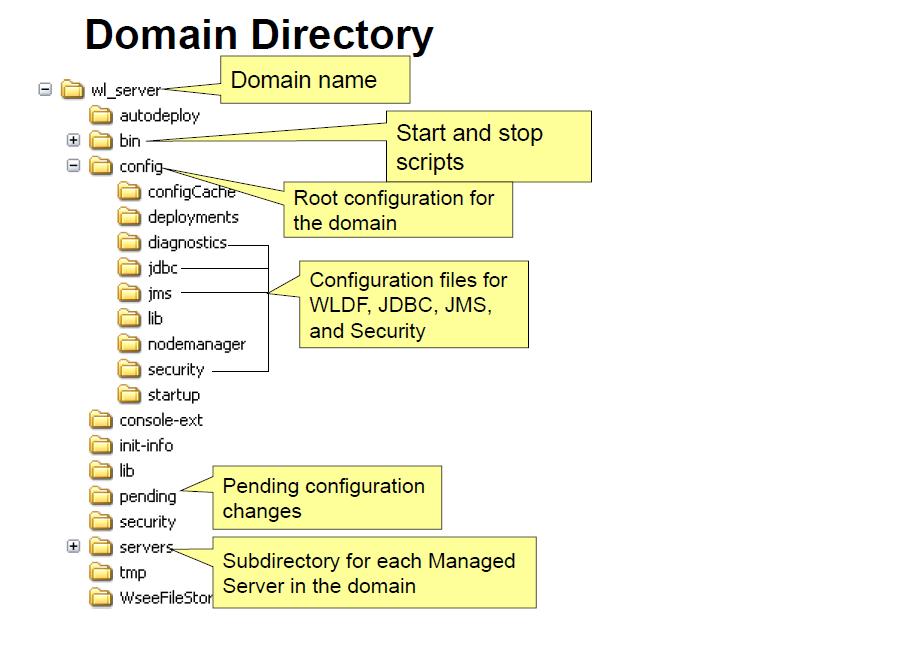
domain-name: The
name of this directory is the name of the domain.
Autodeploy: in development mode,
apps and files are automatically deployed
Bin:
contains scripts that
are used in the process of starting and stopping the Administration Server and
the Managed Servers in the domain. can optionally contain other scripts of
domain-wide interest,
config:
contains the current
configuration and deployment state of the domain. The central domain
configuration file, config.xml, resides in this directory.
config/configCache: Contains data that is
used to optimize performance when validating changes in the domain's
configuration documents.
config/diagnostics:
contains system
modules for the WebLogic Diagnostic
Framework.
config/jdbc: contains system
modules for global JDBC modules that can be configured directly from JMX
config/jms: contains system
modules for JMS
config/lib:
not used in the
current release of WebLogic Server.
config/nodemanager: holds configuration
information for connection to the Node Manager.
config/security:
contains system
modules for the security framework. It contains one security provider
configuration extension for each kind of security provider in the domain's
current realm.
config/startup:
contains system
modules that contain startup plans. Startup plans are used to generate shell
scripts that can be used as part of server startup.
configArchive: contains a set of JAR
files that save the domain's configuration state. Just before pending changes
to the configuration are activated, the domain's existing configuration state,
consisting of the config.xml file and the other related configuration files, is
saved in a versioned JAR file with a name like config.jar#1, config.jar#2, etc.
console-ext:
contains extensions
to the Administration Console, which enable you to add content to the WebLogic Server
Administration Console, replace content, and change the logos, styles and
colors without modifying the files that are installed with WebLogic Server.
init-info:
contains files used
for WebLogic domain provisioning.
lib:
Any JAR files you put
in this directory are added to the system classpath
of each server instance in the domain when the server's Java virtual machine
starts.
pending:
contains domain
configuration files representing configuration changes that have been
requested, but not yet activated.
security:
holds
security-related files that are the same for every WebLogic Server instance in
the domain:
SerializedSystemIni.dat
This directory also
holds security-related files that are only needed by the domain's
Administration Server:
DefaultAuthorizerInit.ldift
DefaultAuthenticatorInit.ldift
DefaultRoleMapperInit.ldift
servers:
contains one
subdirectory for each WebLogic Server instance in
the domain. The subdirectories contain data that is specific to each server
instance.
servers/server-name: the
server directory for the WebLogic Server instance with
the same name as the directory.
servers/server-name/bin: holds
executable or shell files that can be or must be different for each server.
servers/server-name/cache: holds
directories and files that contain cached data.
servers/server-name/cache/EJBCompilerCache: cache for compiled EJBs.
servers/server-name/data: holds
files that maintain persistent per-server state used to run the WebLogic Server instance,
other than security state, as opposed to temporary, cached or historical
information.
servers/server-name/data/ldap: holds
the embedded LDAP database. The runtime security state for the WebLogic Server instance is
persisted in this directory.
servers/server-name/data/store: holds
WebLogic persistent stores.
servers/server-name/logs: holds
logs and diagnostic information.
servers/server-name/logs/diagnostic_images: holds information created by the Server Image Capture
component of WLDF
servers/server-name/logs/jmsServers: contains
one subdirectory for each JMS server in the WebLogic
Server instance. Each such subdirectory contains the logs for that JMS server.
servers/server-name/logs/connector: the default base directory for connector module (JCA ResourceAdapter) logs.
servers/server-name/security: holds
security-related files that can be or must be different for each WebLogic Server instance. The
file boot.properties is an example of a
file that resides here because it can differ from one server to the next. This
directory also maintains files related to SSL keys.
servers/server-name/tmp
This directory holds
temporary directories and files that are created while a server instance is
running. For example, a JMS paging directory is automatically created here
unless another location is specified. Files in this directory must be left
alone while the server is running, but may be freely deleted when the server
instance is shut down.
tmp: stores temporary
files used in the change management process.

As a performance
optimization, WebLogic Server does not
store most of its default values in the domain's configuration files. In some
cases, this optimization prevents XML elements from being written to the
configuration files. For example, if you never modify the default logging
severity level for a domain while the domain is active, the config.xml file
does not contain an XML element for the domain's logging configuration.



weblogic.Deployer
Command line tool for
deploying and undeploying applications
More
info:
http://e-docs.bea.com/wls/docs100/deployment/deploy.html http://e-docs.bea.com/wls/docs100/admin_ref/cli.html
http://e-docs.bea.com/common/docs100/confgwiz/index.html
http://e-docs.bea.com/common/docs100/interm/config.html
http://e-docs.bea.com/common/docs100/tempbuild/index.html
http://e-docs.bea.com/common/docs100/tempref/index.html
http://e-docs.bea.com/wls/docs100/intro/console.html
More info:
weblogic.Admin
Command-line
interface that you can use to administer, configure, and monitor WebLogic Server
Deprecated. Replaced
by WLST Online
More
info:

More info:



More
info:


Using
WLST Offline
Without connecting to
a running WebLogic Server instance, you
can use WLST to create domain templates, create a new domain based on existing
templates, or extend an existing, inactive domain. You cannot use WLST offline
to view performance data about resources in a domain or modify security data
(such as adding or removing users).
WLST offline provides
read and write access to the configuration data that is persisted in the
domain's config directory or in a domain template JAR created using Template
Builder. For information about a domain's configuration documents, see Domain
Configuration Schema Reference and other schema reference documents listed on the BEA WebLogic 10.0 Reference page.
Note the following
restrictions for modifying configuration data with WLST offline:
BEA recommends that
you do not use WLST offline to manage the configuration of an active domain.
Offline edits are ignored by running servers and can be overwritten by JMX
clients such as WLST online or the WebLogic
Server Administration Console.
As a performance
optimization, WebLogic Server does not
store most of its default values in the domain's configuration files. In some
cases, this optimization prevents entire management objects from being
displayed by WLST offline (because WebLogic
Server has never written the corresponding XML elements to the domain's
configuration files). For example, if you never modify the default logging
severity level for a domain while the domain is active, WLST offline will not
display the domain's Log management object. If you want to change the default
value of attributes whose management object is not displayed by WLST offline,
you must first use the create command to create the management object. Then you
can cd to the management
object and change the attribute value. See create.
Using
WLST Online
You can use WLST to
connect to a running Administration Server and manage the configuration of an
active domain, view performance data about resources in the domain, or manage
security data (such as adding or removing users). You can also use WLST to connect
to Managed Servers, but you cannot modify configuration data from Managed
Servers.
WLST online is a Java
Management Extensions (JMX) client. It interacts with a server's in-memory
collection of Managed Beans (MBeans), which are Java
objects that provide a management interface for an underlying resource. For
information on WebLogic Server MBeans, see " Understanding WebLogic Server MBeans" in Developing
Custom Management Utilities with JMX.








My Work: Weblogic Server Overview Topology, Configuration And Administration >>>>> Download Now
ReplyDelete>>>>> Download Full
My Work: Weblogic Server Overview Topology, Configuration And Administration >>>>> Download LINK
>>>>> Download Now
My Work: Weblogic Server Overview Topology, Configuration And Administration >>>>> Download Full
>>>>> Download LINK RK